
تجربه هایی از یادگیری عمیق و شبکه های عصبی
سال 89 زمانی که دانشجوی لیسانس فناوری اطلاعات بودم، یکی از زمینه هایی که علاقه داشتم ( به جز شبکه و برنامه نویسی سیستمی و امنیت و …) یادگیری ماشین و پردازش تصویر بود.
یکی از نتایج اکتشافات من در اون زمان ها، آشنایی با OpenCV و Haar Cascade برای تشخیص چهره بود.
اما اون زمان اونجور که باید مطالعه میکردم و بهش میپرداختم، براش زمان نذاشتم.
تا اینکه دو سال پیش آتش این علاقه دوباره شعله ور شد و برای ارشد هوش مصنوعی اقدام کردم.
چند ماه بعد از قبولی در دانشگاه، تصمیم گرفتم تا مباحث شبکه های عصبی و یادگیری عمیق رو کاربردی تر دنبال کنم.
اول یک آموزش خیلی خوب از سایت Udacity پیدا کردم (Intro to TensorFlow for Deep Learning) که یادگیری عمیق رو با TensorFlow 2 یاد میده.
همزمان که درسا رو پیش میبردم، یک کتاب خوب هم پیدا کردم (Intelligent Mobile Projects with TensorFlow) که مباحث پایه ای خیلی جالبی رو یاد میده، این دو تا کمکم کردن که یک تصویر بزرگتر (Big Picture) و مبتنی بر برنامه نویسی رو، نسبت به شبکه های عصبی پیدا کنم.
بعد تصمیم گرفتم برای پروژه عملی، الگوریتمی که چند ماه قبل تر دیده بودم رو برای تشخیص چهره پیاده سازی کنم.
الگوریتم YOLO روشی پیشنهاد میده که میشه خیلی سریع و دقیق، فقط با یک بار پردازش یک شبکه عصبی، مکان اشیاء مختلف به همراه اسمشون رو در یک تصویر پیدا کرد.
تا به حال سه تا نسخه از این الگوریتم منتشر شده، که من قصد داشتم نسخه اول این الگوریتم رو پیاده سازی کنم.
شروع کردم به خواندن مقاله نسخه اول الگوریتم YOLO، یک صدایی توی ذهنم میگفت اگه متن مقاله رو توی دفترم بنویسم، باعث میشه مباحث رو بهتر بفهمم و بهتر یادم بمونه (چرت میگفت)، قسمت های مهم مقاله رو توی دفترم نوشتم، حدود 11 صفحه، گفتم حالا وقتشه کداشو بنویسم.
از ابتدای داستان تا الان، 1 ماه گذشته.
با خودم گفتم، درسته که قراره چرخ رو از اول اختراع کنم، اما قرار نیست که بیش از حد وقتمو هدر بدم، مخصوصا وقتی این فرمولای ریاضی با این سمبل های یونانی عجیب غریب رو کامل متوجه نشدم.
پس، بهتره برم ببینم چه کسی این کارو انجام داده و کدشو به صورت متن باز در گیت هاب قرار داده.
کلی پیاده سازی برای YOLO نسخه 1 بر بستر Keras و TensorFlow پیدا کردم.
اما اونایی که کاملا با Keras نوشته شده بودن رو خیلی راحت تر میشد مهاجرت داد به TensorFlow 2.0، پس 2 تا از منبع کدها رو گلچین کردم و گفتم خوب دیگه چی؟
گفتم کسی قبل از من نبوده که بخواد با YOLO تشخیص چهره انجام بده؟
یک سرچ توی اینترنت زدم و دیدم چرا، یک استاد دانشگاهی انگار از برزیل بود، دقیقا یادم نیست، یک مقاله تو سایت Medium نوشته که با استفاده از YOLO و کمی دستکاری شبکه عصبی، تشخیص چهره انجام داده، تازه کداشم گذاشته برای استفاده!
خیلی خوشحال و خوش خیال، کداشو گرفتم و بعد از کلی مصیبت آماده به اجرا کردم (نصب TensorFlow و CUDA و CuDNN و Visual Studio) بعد دیدم یک قسمتی از کداش نیست؟!
قلب کداش نبود!
همون کدایی که میشه باهاش شبکه رو تمرین داد (train کرد).
شاکی شدم دوباره رفتم سراغ مقاله و گیت هابش، دیدم قول داده که این کدا رو میذاره، اما چند ماهه به قولش عمل نکرده، اصلا بنده خدا خیلی وقته انگار نیستش.
کار مثبتی که کرده بود، مدل شبکه عصبیشو گذاشته بود برای تست، و به انگلیسی توضیح داده بود که چطوری دیتاست آماده کرده و خیلی خلاصه گفته بود چطوری شبکه رو train کرده.
برای train کردن شبکه عصبی، از دیتاست WiderFace استفاده کرده بود که یک مرحله تبدیل به TFRecord نیاز داشت، خودش این قسمت رو هم متن باز کداشو گذاشته بود، حالا بماند که این کد تبدیلش کلی باگ داشت و چقدر زمان گذاشتم بفهمم چرا این بنده خدا کداش باگ داره و خودش برای رفعش کاری نکرده.
بعد برداشتم و مدل شبکه عصبیشو مهندسی معکوس کردم، با نرم افزار Netron، این نرم افزار، فرمت های مختلفی از مدل های شبکه های عصبی رو پشتیبانی میکنه.
بهم یک گراف داد که از روش، شبکه رو با Keras پیاده سازی کردم، ممکنه بپرسین چرا همون شبکه عصبی توی مقاله رو پیاده سازی نکردم؟
چون عرضم به خدمتتون که کارت گرافیک من 2 گیگابایت بیشتر رم نداره، و شبکه عصبی پیشنهاد شده در مقاله روی حافظه کارت گرافیک من جا نمیشه، اما مدل پیشنهادی این بنده خدا نصف مدل مقاله پارامتر داشت و تونستم روی کارت گرافیک نفتیم اجراش کنم.
بعدش، شب ها و روزها گذشت، خیلی چیزا رو تست کردم، اما من نتیجه مطلوب نگرفتم بلکه خیلی وقتا نتایج بدتر میشد!
پس دست به دعا گشودم و شروع کردم به تحقیق که چرا شبکه های عصبی خوب train نمیشن، از یکی از دوستان که مهاجرت کرده استرالیا هم مشورت گرفتم و نهایتا بعد از 1 ماه تحقیق و مطالعه و کد نویسی و آزمایش های مختلف زمان بر! بله! زمان بر!، تقریبا به نتیجه دلخواهم رسیدم.
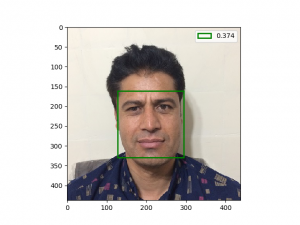
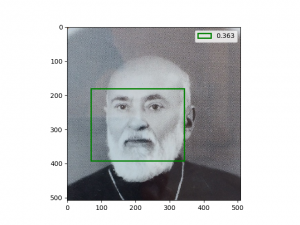

در ادامه مهم ترین تجربه هایی که بدست آوردم رو میگم، شما هم اگه تجربه بخصوصی دارین با من به اشتراک بذارین
شبکه عصبی با پارامترهای کمتر، مناسب موبایل ها و کامپیوتر ضعیف من
من نیازی به دقت خیلی زیاد نداشتم (البته سخت افزار مناسبش رو هم نداشتم)، و بیشتر هم دنبال تشخیص بلادرنگ (Real Time) روی موبایل بودم، پس تحقیق کردم ببینم چه شبکه های عصبی مخصوص موبایل تولید شده که برخورد کردم با MobileNet که نسخه 1 و 2 داره.
این موبایل-نت به دفعات در پروژه های مختلف گوگل استفاده شده و همه از نتایجش راضی بودن، این شد که من هم ازش استفاده کردم.
همین تصمیم باعث شد که train کردن های من که 2-3 روز طول میکشید حالا برسن به 8 ساعت یا کمتر.
دیتاست خوب و دقت در نشانه گذاری ها
شبکه عصبی مورد استفاده این مطلب، متشکل از دو تا بخشه، بخشی که ویژگی ها رو تشخیص میده (Feature Detection) و بخشی که رگرسیون (Regression) یا پیدا کردن مختصات رو انجام میده.
این شبکه ها لایه های Convolutional دارند، و end to end هستند، یعنی پروسه تشخیص ویژگی ها توسط خود شبکه انجام میشه و انسان این کار رو مهندسی نمیکنه.
اگه میخواین شبکه، مهم ترین کارش، که تشخیص ویژگی هاست رو خوب انجام بده، خوب هم نشد، حداقل بتونه انجامش بده (دچار Underfitting نشیم)؟! باید دیتاست از کیفیت و تنوع خوبی برخوردار باشه!
دیتاست WiderFace به شدت دچار نقص بود، از صورت های بسیار کوچک که حتی انسان هم نمیتونه درست تشخیص بده، تا جعبه محدوده های (Bounding Box) ناقص، مثلا بدیهی ترین صورت ها در تصویرها نشانه گذاری نشده بودن و شبکه عصبی مواجه بود با یک مشت False Negative و False Positive.
با خودم گفتم یا باید دیتاست خودم رو بسازم یا یک دیتاست بهتر انتخاب کنم، آخر سر یک دیتاست خوب از imdb پیدا کردم که پر از صورت هنرپیشه ها بود.
اولین نتایج مثبتم رو از همینجا گرفتم!
تنوع داده ها و ایجاد افزونگی داده
شبکه train شده روی دیتاست imdb روی تصاویر مربعی شکل، با چرخش کم صورت و بدون حالات شدید چهره (خنده، غم و … شدید) خوب عمل میکرد، اما این برای دنیای واقعی کافی نیست.
حالا یا باید یک دیتاست جدید پیدا میکردم که تنوع بالایی داشته باشه، یا خودم همین دیتاست رو دستکاری میکردم.
معمولا دیتاست هایی وجود دارن که در اسمشون عبارت wild وجود داره، یعنی در شرایط مختلف عکسبرداری شده و تنوع بسیار بالایی داره، ولی خوب الزاما این ها به خوب نشانه گذاری نشدن، نمونش همین WiderFace.
توی اکثر مقاله ها، با اینکه دیتاست های خوبی در دسترس داشتن، خودشون افزونگی داده هم انجام داده ان، من هم گفتم دنباله رو راه همین ها باشم (افزونگی برابر است با Overfitting کمتر)، پس شروع کردم به:
ایجاد تصاویر با روشنایی های (Brightness) مختلف، ایجاد تصاویر با نویز (Noise)، ایجاد تصاویر با جابجایی (Translation) در فضای دو بعدی، ایجاد تصاویر با چرخش (Rotation) در فضای دو بعدی، ایجاد تصاویر با مقیاس (Scale) در فضای دو بعدی.
حالا شبکه ای که با این تصاویر train کردم، تصاویر بیشتری رو تشخیص میداد، اما هنوز هم یک جای کار میلنگید.
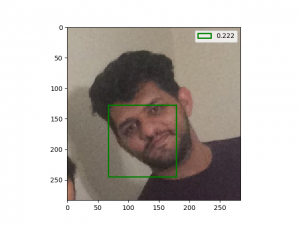
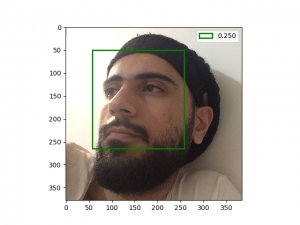
شبکه من توی تشخیص چهره های بسیار خندان یا چهره هایی که چرخش زیاد داشتن، مشکل داشت!
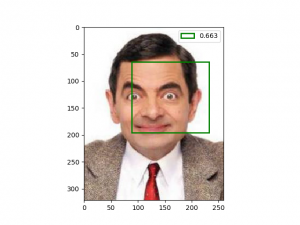
مثلا این مستر بین با این صورتش! خوب همچین چهره ای در دیتاست imdb وجود نداشته، یا اگه بوده خیلی کم بوده و شبکه خیلی بهش عادت نداره.
پس من نیاز داشتم به:
حالات احساسی مختلف
حالات چرخش های سر مختلف
البته این دو مورد آخر رو هنوز کاری براشون نکردم.
انتخاب درست بهینه ساز
در مقاله های YOLO از بهینه ساز SGD استفاده شده، یکی از موانع نتیجه گرفتن من همین مورد بود.
شروع کردم چندتا مقاله دیگه خوندم، دیدم دارن از بهینه ساز Adam استفاده میکنن و دیدم خیلی ها میگن که استفاده درست از SGD سخته و به راحتی نمیشه ازش نتیجه گرفت.
پس من هم رفتم سراغ Adam که یک بهینه ساز آداپتیوه (Adaptive)، و جالبه براتون بگم که سرعت یادگیری رو حداقل 20% بیشتر کرد و دقت کار من چند برابر شد.
بازپینگ: تشخیص اشیاء با فلاتر و تنسورفلو لایت - علی اشتهاری پور