تبدیل encoding و character set با python – وقتی به جای یونیکد، کاراکترهای عربی ویندوزی داریم
داستان از اونجایی شروع شد که، قرار شد یک نفر، یک فایل word رو بگیره و محتواشو تقسیم بندی کنه تو چند تا پوشه و چند تا فایل.
روزی که برام خروجی رو آورد، شروع کردم به چک کردن ساختاری که خواسته بودم.
فایل های انگلیسی همه درست بودن، اما فایل های فارسی، کلا شامل حروف درب و داغون غیر قابل خوندن بودن.
یک چیزی شبیه به این عبارت: “ÚãÇÏ ãåÇÌÑÊ ÈÒä”
اولین چیزی که به ذهنم رسید، این بود که قدیم ترا عمدتا با زیر نویس فیلم ها و سریالا مشکل داشتیم.
راه حلشم معمولا این بود که encoding زیر نویس رو توی برنامه پخش کننده (که من VLC استفاده میکردم) به Arabic Windows-1256 تغییر بدیم.
دارم جمع میبندم چون این مشکل تو ایران همگانی بود :))
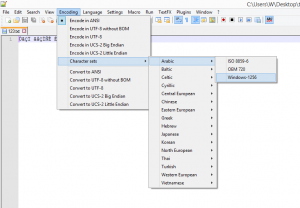
خلاصه این فایل عجیب غریبه رو با Notepad++ باز کردم و انکودینگ رو تغییر دادم و بالاخره فایل خوانا شد.
برای من صرفه نداره که حدود هزار تا فایل رو بیام دستی با Notepad++ درست کنم، پس از زبان پایتون کمک میگیرم تا همه ی کارا رو برام انجام بده.
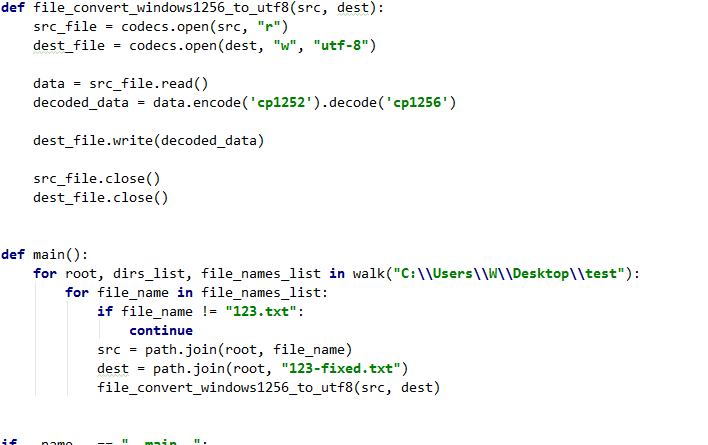
from os import walk, path
import codecs
def file_convert_windows1256_to_utf8(src, dest):
src_file = codecs.open(src, "r")
dest_file = codecs.open(dest, "w", "utf-8")
data = src_file.read()
decoded_data = data.encode('cp1252').decode('cp1256')
dest_file.write(decoded_data)
src_file.close()
dest_file.close()
def main():
for root, dirs_list, file_names_list in walk("C:\\Users\\W\\Desktop\\test"):
for file_name in file_names_list:
if file_name != "123.txt":
continue
src = path.join(root, file_name)
dest = path.join(root, "123-fixed.txt")
file_convert_windows1256_to_utf8(src, dest)
if __name__ == "__main__":
main()
البته اینجا، ما کاراکترهای عربی رو تبدیل نکردیم به فارسی، که این هم تمرین خیلی خوبی میتونه باشه.
حالا کامنت بذارین، اون عبارت که بالاتر نوشتم، به فارسی چیه؟